New memisc release 0.99.20.1 improves compatibility with RStudio and “tidyverse”¶
Release 0.99.20.1. has been published on CRAN. It improves the way the package interoperates with RStudio and “tidyverse”. In particular:
- A function
view()provides a generic interface to the GUI functionView()in base R and RStudio. It makes it possible to extend it to data objects of the classes “data.set”, “codeplan”, “description”, and “importer”.
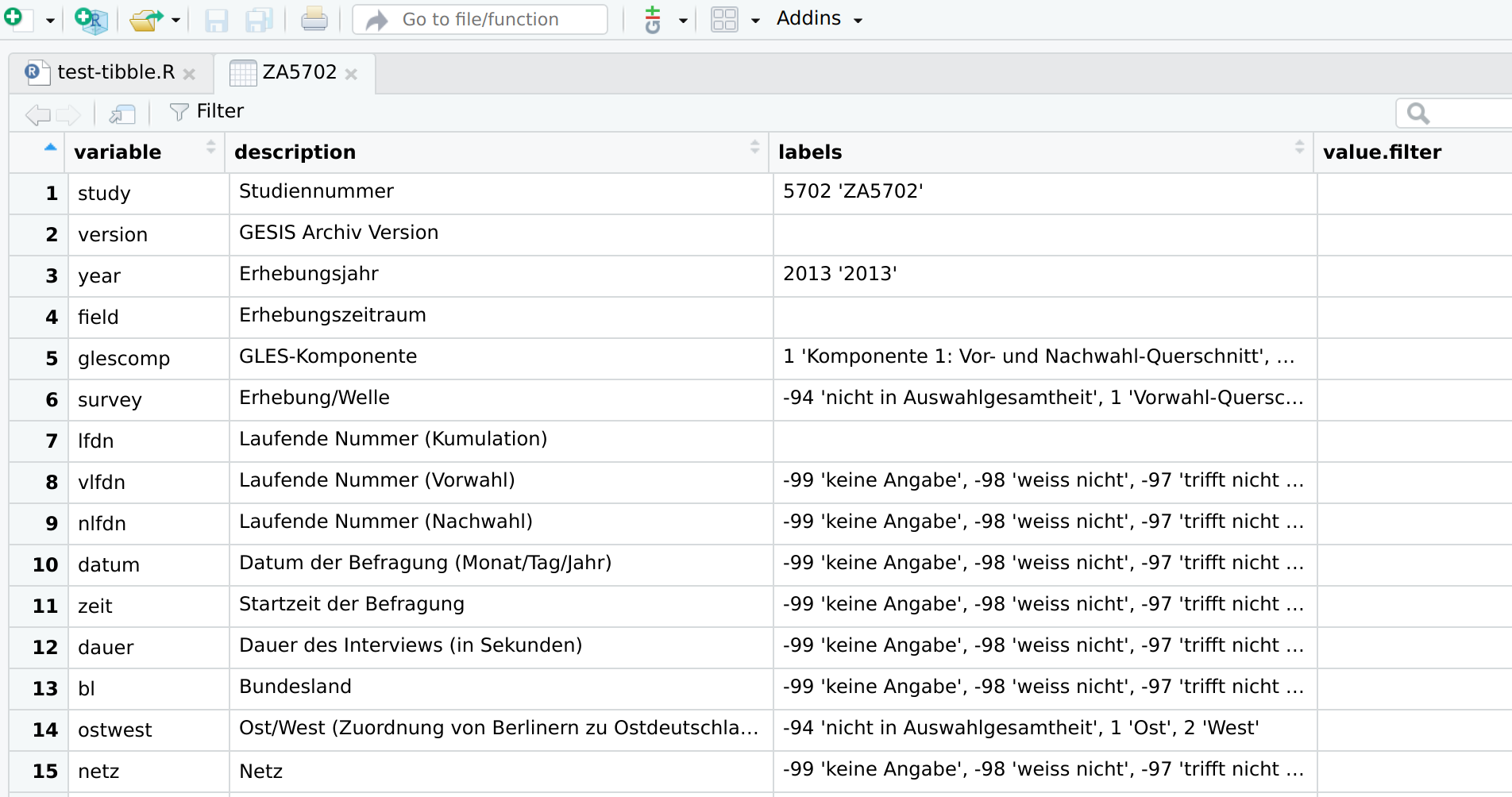
The result of view(ZA5702), where ZA5702 is an “importer” object
created by spss.file("ZA5702_v2-0-0.sav").¶
- A
as_tibble()method for “data.set” objects allows to transfer these objects more easiliy into the “tidyverse”, i.e. facilitates the use of functions from these package ecosystem on data sets imported or created with memisc. Anas_haven()function translates “data.set” objects into “tibbles” objects with that extra information that the “haven” package adds to “tibbles” imported with the help of that package. This should allow to view and post-process data imported with memisc more or less the same way as if the data were imported with “haven”. - When a “data.set” object is translated into a data frame using
as.data.frame(),as_tibble(),as_haven(), orviewPrep()(the internal function used byview()to prepare data for being viewed) the “description” of the variables (or “item” objects) are retained as “label” attributes, so that labels are visible when viewed in RStudio.
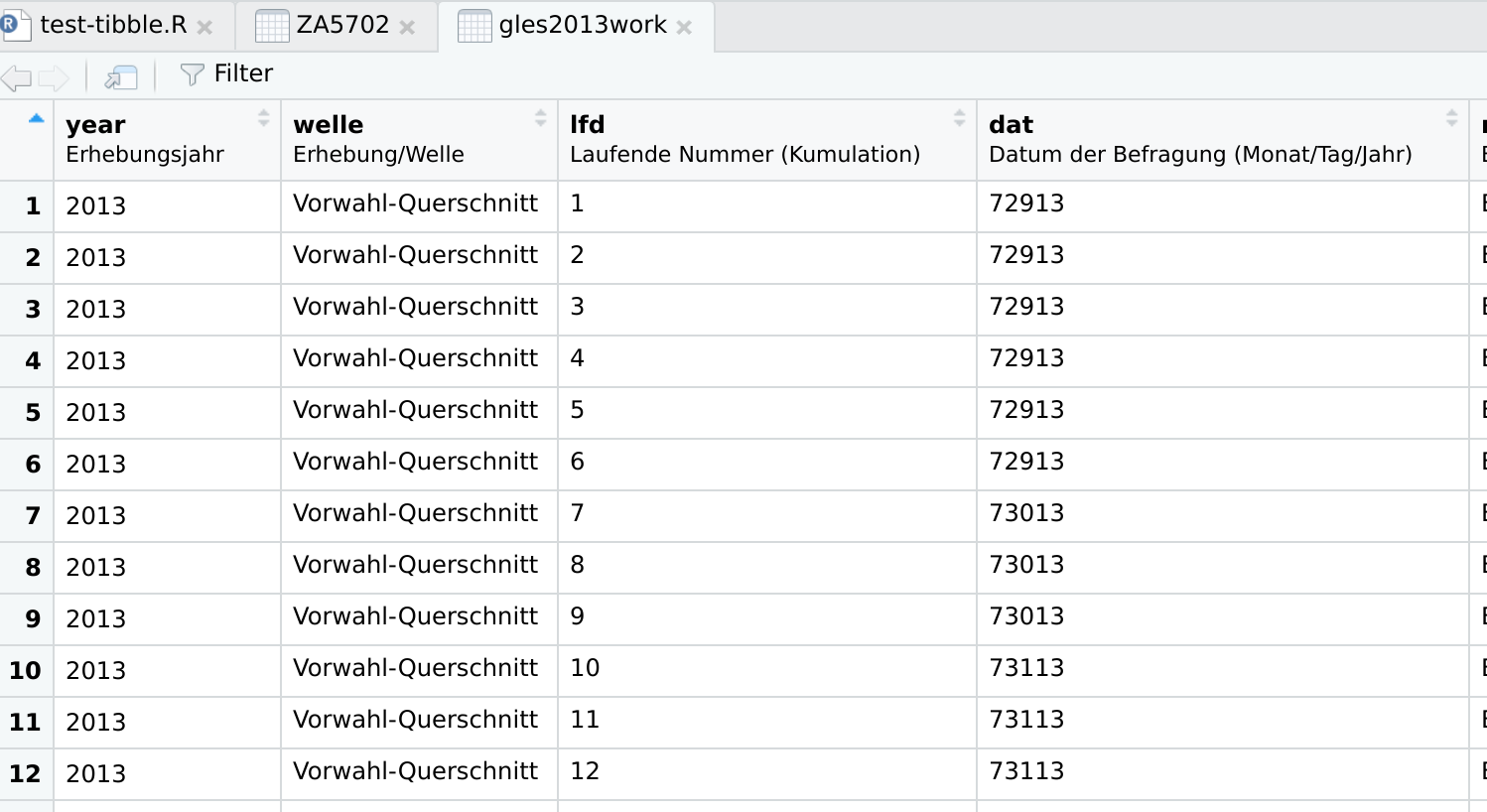
The result of view(gles2013work), where gles2013work is a “data.set” object
created by subset(ZA5702,...).¶
- A
List()function adds names to its elements by deparsing arguments in the same way asdata.frame()does. - A new function
Groups()allows to split a data frame or a “data.set” into group based on factors in a more convenient way. There are methods ofwith.grouped.data with()andwithin.grouped.data within()to deal with resulting objects of class “grouped.data”. For example, thewithin.grouped.data within()method allows to substract group means from the observations within groups.withinGroups()allows to split a data frame or “data.set” objects into groups, make within-group computations and recombine the groups into the order of the original data frame or “data.set” object. -
Stata.file()now handles files in format rev. 117 and later as they are created by Stata version later than 13. - User definded missing values are now reported in separate tables in entries
created by
codebook()even if these entries refer to “item” objects with measurement level “interval” or “ratio”. - If the annotation or the labels of a non-item is set to
NULLthis no longer causes an error. - Changing varible names to lowercase while importing data sets with
Stata.file(),spss.portable.file(), andspss.system.file()is now optional. - Importer methods
Stata.file(),spss.portable.file(), andspss.system.file()now have optional arguments that allow to deal with variable labels or value labels in non-native encoding (e.g.CP1252on autf-8platform). - A function
spss.file()acts as a common interface tospss.portable.file()andspss.system.file(). - The function
head()andtail()now work with “data.set” and “importer” objects in the same sensible way as they do with data frames. - The function
recode()behaves more coherently: If a labelled vector is the result ofrecode()it gets themeasurement measurement level“nominal”. Factor levels explictly created first come first in the order of factor levels.
